We beforehand shared our insights on the techniques now we have honed whereas working LLM purposes. Ways are granular: they’re the precise actions employed to attain particular targets. We additionally shared our perspective on operations: the higher-level processes in place to help tactical work to attain targets.
However the place do these targets come from? That’s the area of technique. Technique solutions the “what” and “why” questions behind the “how” of techniques and operations.

Study sooner. Dig deeper. See farther.
We offer our opinionated takes, similar to “no GPUs earlier than PMF” and “concentrate on the system not the mannequin”, to assist groups determine the place to allocate scarce assets. We additionally recommend a roadmap for iterating in direction of a terrific product. This ultimate set of classes solutions the next questions:
- Constructing vs. Shopping for: When must you prepare your personal fashions, and when must you leverage current APIs? The reply is, as at all times, “it relies upon”. We share what it is determined by.
- Iterating to One thing Nice: How will you create an enduring aggressive edge that goes past simply utilizing the most recent fashions? We talk about the significance of constructing a strong system across the mannequin and specializing in delivering memorable, sticky experiences.
- Human-Centered AI: How will you successfully combine LLMs into human workflows to maximise productiveness and happiness? We emphasize the significance of constructing AI instruments that help and improve human capabilities relatively than making an attempt to interchange them solely.
- Getting Began: What are the important steps for groups embarking on constructing an LLM product? We define a fundamental playbook that begins with immediate engineering, evaluations, and information assortment.
- The Way forward for Low-Price Cognition: How will the quickly reducing prices and rising capabilities of LLMs form the way forward for AI purposes? We look at historic tendencies and stroll via a easy technique to estimate when sure purposes may change into economically possible.
- From Demos to Merchandise: What does it take to go from a compelling demo to a dependable, scalable product? We emphasize the necessity for rigorous engineering, testing, and refinement to bridge the hole between prototype and manufacturing.
To reply these troublesome questions, let’s assume step-by-step…
Technique: Constructing with LLMs with out Getting Out-Maneuvered
Profitable merchandise require considerate planning and hard prioritization, not limitless prototyping or following the most recent mannequin releases or tendencies. On this ultimate part, we glance across the corners and take into consideration the strategic issues for constructing nice AI merchandise. We additionally look at key trade-offs groups will face, like when to construct and when to purchase, and recommend a “playbook” for early LLM utility improvement technique.
No GPUs earlier than PMF
To be nice, your product must be greater than only a skinny wrapper round someone else’s API. However errors in the other way could be much more pricey. The previous yr has additionally seen a mint of enterprise capital, together with an eye-watering six billion greenback Collection A, spent on coaching and customizing fashions with no clear product imaginative and prescient or goal market. On this part, we’ll clarify why leaping instantly to coaching your personal fashions is a mistake and take into account the function of self-hosting.
Coaching from scratch (virtually) by no means is smart
For many organizations, pre-training an LLM from scratch is an impractical distraction from constructing merchandise.
As thrilling as it’s and as a lot because it looks as if everybody else is doing it, creating and sustaining machine studying infrastructure takes numerous assets. This contains gathering information, coaching and evaluating fashions, and deploying them. When you’re nonetheless validating product-market match, these efforts will divert assets from creating your core product. Even in case you had the compute, information, and technical chops, the pretrained LLM might change into out of date in months.
Take into account the case of BloombergGPT, an LLM particularly educated for monetary duties. The mannequin was pretrained on 363B tokens and required a heroic effort by 9 full-time staff, 4 from AI Engineering and 5 from ML Product and Analysis. Regardless of this effort, it was outclassed by gpt-3.5-turbo and gpt-4 on these monetary duties inside a yr.
This story and others prefer it means that for many sensible purposes, pretraining an LLM from scratch, even on domain-specific information, shouldn’t be the very best use of assets. As an alternative, groups are higher off fine-tuning the strongest open-source fashions obtainable for his or her particular wants.
There are after all exceptions. One shining instance is Replit’s code mannequin, educated particularly for code-generation and understanding. With pretraining, Replit was in a position to outperform different fashions of enormous sizes similar to CodeLlama7b. However as different, more and more succesful fashions have been launched, sustaining utility has required continued funding.
Don’t fine-tune till you’ve confirmed it’s obligatory
For many organizations, fine-tuning is pushed extra by FOMO than by clear strategic considering.
Organizations spend money on fine-tuning too early, attempting to beat the “simply one other wrapper” allegations. In actuality, fine-tuning is heavy equipment, to be deployed solely after you’ve collected loads of examples that persuade you different approaches gained’t suffice.
A yr in the past, many groups had been telling us they had been excited to fine-tune. Few have discovered product-market match and most remorse their resolution. When you’re going to positive tune, you’d higher be actually assured that you simply’re set as much as do it time and again as base fashions enhance—see the “The mannequin isn’t the product” and “Construct LLMOps” under.
When may fine-tuning really be the proper name? If the use-case requires information not obtainable within the mostly-open web-scale datasets used to coach current fashions—and in case you’ve already constructed an MVP that demonstrates the present fashions are inadequate. However watch out: if nice coaching information isn’t available to the mannequin builders, the place are you getting it?
In the end, keep in mind that LLM-powered purposes aren’t a science truthful undertaking, funding in them must be commensurate with their contribution to your corporation’ strategic targets and its aggressive differentiation.
Begin with inference APIs, however don’t be afraid of self-hosting
With LLM APIs, it’s simpler than ever for startups to undertake and combine language modeling capabilities with out coaching their very own fashions from scratch. Suppliers like Anthropic, and OpenAI provide basic APIs that may sprinkle intelligence into your product with just some traces of code. Through the use of these companies, you possibly can cut back the hassle spent and as a substitute concentrate on creating worth in your prospects—this lets you validate concepts and iterate in direction of product-market match sooner.
However, as with databases, managed companies aren’t the proper match for each use case, particularly as scale and necessities enhance. Certainly, self-hosting often is the solely method to make use of fashions with out sending confidential/non-public information out of your community, as required in regulated industries like healthcare and finance, or by contractual obligations or confidentiality necessities.
Moreover, self-hosting circumvents limitations imposed by inference suppliers, like fee limits, mannequin deprecations, and utilization restrictions. As well as, self-hosting provides you full management over the mannequin, making it simpler to assemble a differentiated, prime quality system round it. Lastly, self-hosting, particularly of finetunes, can cut back price at giant scale. For instance, Buzzfeed shared how they finetuned open-source LLMs to cut back prices by 80%.
Iterate to one thing nice
To maintain a aggressive edge in the long term, it’s good to assume past fashions and take into account what is going to set your product aside. Whereas velocity of execution issues, it shouldn’t be your solely benefit.
The mannequin isn’t the product, the system round it’s
For groups that aren’t constructing fashions, the fast tempo of innovation is a boon as they migrate from one SOTA mannequin to the following, chasing positive aspects in context measurement, reasoning functionality, and price-to-value to construct higher and higher merchandise.
This progress is as thrilling as it’s predictable. Taken collectively, this implies fashions are more likely to be the least sturdy part within the system.
As an alternative, focus your efforts on what’s going to supply lasting worth, similar to:
- Analysis chassis: To reliably measure efficiency in your activity throughout fashions
- Guardrails: To stop undesired outputs irrespective of the mannequin
- Caching: To cut back latency and price by avoiding the mannequin altogether
- Information flywheel: To energy the iterative enchancment of every little thing above
These elements create a thicker moat of product high quality than uncooked mannequin capabilities.
However that doesn’t imply constructing on the utility layer is risk-free. Don’t level your shears on the similar yaks that OpenAI or different mannequin suppliers might want to shave in the event that they need to present viable enterprise software program.
For instance, some groups invested in constructing customized tooling to validate structured output from proprietary fashions; minimal funding right here is vital, however a deep one shouldn’t be a great use of time. OpenAI wants to make sure that if you ask for a perform name, you get a legitimate perform name—as a result of all of their prospects need this. Make use of some “strategic procrastination” right here, construct what you completely want, and await the apparent expansions to capabilities from suppliers.
Construct belief by beginning small
Constructing a product that tries to be every little thing to everyone seems to be a recipe for mediocrity. To create compelling merchandise, firms must specialise in constructing memorable, sticky experiences that hold customers coming again.
Take into account a generic RAG system that goals to reply any query a consumer may ask. The dearth of specialization signifies that the system can’t prioritize current info, parse domain-specific codecs, or perceive the nuances of particular duties. Consequently, customers are left with a shallow, unreliable expertise that doesn’t meet their wants.
To handle this, concentrate on particular domains and use circumstances. Slim the scope by going deep relatively than vast. It will create domain-specific instruments that resonate with customers. Specialization additionally lets you be upfront about your system’s capabilities and limitations. Being clear about what your system can and can’t do demonstrates self-awareness, helps customers perceive the place it may well add probably the most worth, and thus builds belief and confidence within the output.
Construct LLMOps, however construct it for the proper motive: sooner iteration
DevOps shouldn’t be essentially about reproducible workflows or shifting left or empowering two pizza groups—and it’s undoubtedly not about writing YAML recordsdata.
DevOps is about shortening the suggestions cycles between work and its outcomes in order that enhancements accumulate as a substitute of errors. Its roots return, through the Lean Startup motion, to Lean manufacturing and the Toyota Manufacturing System, with its emphasis on Single Minute Change of Die and Kaizen.
MLOps has tailored the type of DevOps to ML. We’ve got reproducible experiments and now we have all-in-one suites that empower mannequin builders to ship. And Lordy, do now we have YAML recordsdata.
However as an trade, MLOps didn’t adapt the perform of DevOps. It didn’t shorten the suggestions hole between fashions and their inferences and interactions in manufacturing.
Hearteningly, the sector of LLMOps has shifted away from fascinated about hobgoblins of little minds like immediate administration and in direction of the onerous issues that block iteration: manufacturing monitoring and continuous enchancment, linked by analysis.
Already, now we have interactive arenas for impartial, crowd-sourced analysis of chat and coding fashions—an outer loop of collective, iterative enchancment. Instruments like LangSmith, Log10, LangFuse, W&B Weave, HoneyHive, and extra promise to not solely acquire and collate information about system outcomes in manufacturing, but additionally to leverage them to enhance these methods by integrating deeply with improvement. Embrace these instruments or construct your personal.
Don’t construct LLM options you should buy
Most profitable companies will not be LLM companies. Concurrently, most companies have alternatives to be improved by LLMs.
This pair of observations typically misleads leaders into rapidly retrofitting methods with LLMs at elevated price and decreased high quality and releasing them as ersatz, self-importance “AI” options, full with the now-dreaded sparkle icon. There’s a greater method: concentrate on LLM purposes that actually align along with your product targets and improve your core operations.
Take into account just a few misguided ventures that waste your staff’s time:
- Constructing customized text-to-SQL capabilities for your corporation.
- Constructing a chatbot to speak to your documentation.
- Integrating your organization’s data base along with your buyer help chatbot.
Whereas the above are the hellos-world of LLM purposes, none of them make sense for just about any product firm to construct themselves. These are basic issues for a lot of companies with a big hole between promising demo and reliable part—the customary area of software program firms. Investing useful R&D assets on basic issues being tackled en masse by the present Y Combinator batch is a waste.
If this seems like trite enterprise recommendation, it’s as a result of within the frothy pleasure of the present hype wave, it’s simple to mistake something “LLM” as cutting-edge, accretive differentiation, lacking which purposes are already previous hat.
AI within the loop; people on the heart
Proper now, LLM-powered purposes are brittle. They required an unbelievable quantity of safe-guarding, defensive engineering, and stay onerous to foretell. Moreover, when tightly scoped these purposes could be wildly helpful. Which means LLMs make glorious instruments to speed up consumer workflows.
Whereas it might be tempting to think about LLM-based purposes absolutely changing a workflow, or standing in for a job-function, as we speak the best paradigm is a human-computer centaur (c.f. Centaur chess). When succesful people are paired with LLM capabilities tuned for his or her fast utilization, productiveness and happiness doing duties could be massively elevated. One of many flagship purposes of LLMs, GitHub CoPilot, demonstrated the ability of those workflows:
“Total, builders informed us they felt extra assured as a result of coding is less complicated, extra error-free, extra readable, extra reusable, extra concise, extra maintainable, and extra resilient with GitHub Copilot and GitHub Copilot Chat than once they’re coding with out it.” – Mario Rodriguez, GitHub
For many who have labored in ML for a very long time, it’s possible you’ll leap to the thought of “human-in-the-loop”, however not so quick: HITL Machine Studying is a paradigm constructed on Human consultants guaranteeing that ML fashions behave as predicted. Whereas associated, right here we’re proposing one thing extra refined. LLM pushed methods shouldn’t be the first drivers of most workflows as we speak, they need to merely be a useful resource.
By centering people, and asking how an LLM can help their workflow, this results in considerably completely different product and design selections. In the end, it is going to drive you to construct completely different merchandise than opponents who attempt to quickly offshore all duty to LLMs; higher, extra helpful, and fewer dangerous merchandise.
Begin with prompting, evals, and information assortment
The earlier sections have delivered a firehose of methods and recommendation. It’s quite a bit to absorb. Let’s take into account the minimal helpful set of recommendation: if a staff desires to construct an LLM product, the place ought to they start?
Over the past yr, we’ve seen sufficient examples to begin changing into assured that profitable LLM purposes observe a constant trajectory. We stroll via this fundamental “getting began” playbook on this part. The core thought is to begin easy and solely add complexity as wanted. A good rule of thumb is that every stage of sophistication usually requires no less than an order of magnitude extra effort than the one earlier than it. With this in thoughts…
Immediate engineering comes first
Begin with immediate engineering. Use all of the methods we mentioned within the techniques part earlier than. Chain-of-thought, n-shot examples, and structured enter and output are virtually at all times a good suggestion. Prototype with probably the most extremely succesful fashions earlier than attempting to squeeze efficiency out of weaker fashions.
Provided that immediate engineering can not obtain the specified stage of efficiency must you take into account fine-tuning. It will come up extra typically if there are non-functional necessities (e.g., information privateness, full management, price) that block using proprietary fashions and thus require you to self-host. Simply ensure those self same privateness necessities don’t block you from utilizing consumer information for fine-tuning!
Construct evals and kickstart a knowledge flywheel
Even groups which are simply getting began want evals. In any other case, you gained’t know whether or not your immediate engineering is adequate or when your fine-tuned mannequin is able to substitute the bottom mannequin.
Efficient evals are particular to your duties and mirror the supposed use circumstances. The primary stage of evals that we advocate is unit testing. These easy assertions detect identified or hypothesized failure modes and assist drive early design selections. Additionally see different task-specific evals for classification, summarization, and so on.
Whereas unit checks and model-based evaluations are helpful, they don’t substitute the necessity for human analysis. Have individuals use your mannequin/product and supply suggestions. This serves the twin goal of measuring real-world efficiency and defect charges whereas additionally amassing high-quality annotated information that can be utilized to finetune future fashions. This creates a optimistic suggestions loop, or information flywheel, which compounds over time:
- Human analysis to evaluate mannequin efficiency and/or discover defects
- Use the annotated information to finetune the mannequin or replace the immediate
For instance, when auditing LLM-generated summaries for defects we would label every sentence with fine-grained suggestions figuring out factual inconsistency, irrelevance, or poor fashion. We will then use these factual inconsistency annotations to prepare a hallucination classifier or use the relevance annotations to coach a reward mannequin to attain on relevance. As one other instance, LinkedIn shared about their success with utilizing model-based evaluators to estimate hallucinations, accountable AI violations, coherence, and so on. of their write-up
By creating property that compound their worth over time, we improve constructing evals from a purely operational expense to a strategic funding, and construct our information flywheel within the course of.
The high-level pattern of low-cost cognition
In 1971, the researchers at Xerox PARC predicted the longer term: the world of networked private computer systems that we are actually residing in. They helped delivery that future by taking part in pivotal roles within the invention of the applied sciences that made it potential, from Ethernet and graphics rendering to the mouse and the window.
However in addition they engaged in a easy train: they checked out purposes that had been very helpful (e.g. video shows) however weren’t but economical (i.e. sufficient RAM to drive a video show was many 1000’s of {dollars}). Then they checked out historic worth tendencies for that expertise (a la Moore’s Legislation) and predicted when these applied sciences would change into economical.
We will do the identical for LLM applied sciences, regardless that we don’t have one thing fairly as clear as transistors per greenback to work with. Take a well-liked, long-standing benchmark, just like the Massively-Multitask Language Understanding dataset, and a constant enter strategy (five-shot prompting). Then, evaluate the associated fee to run language fashions with numerous efficiency ranges on this benchmark over time.
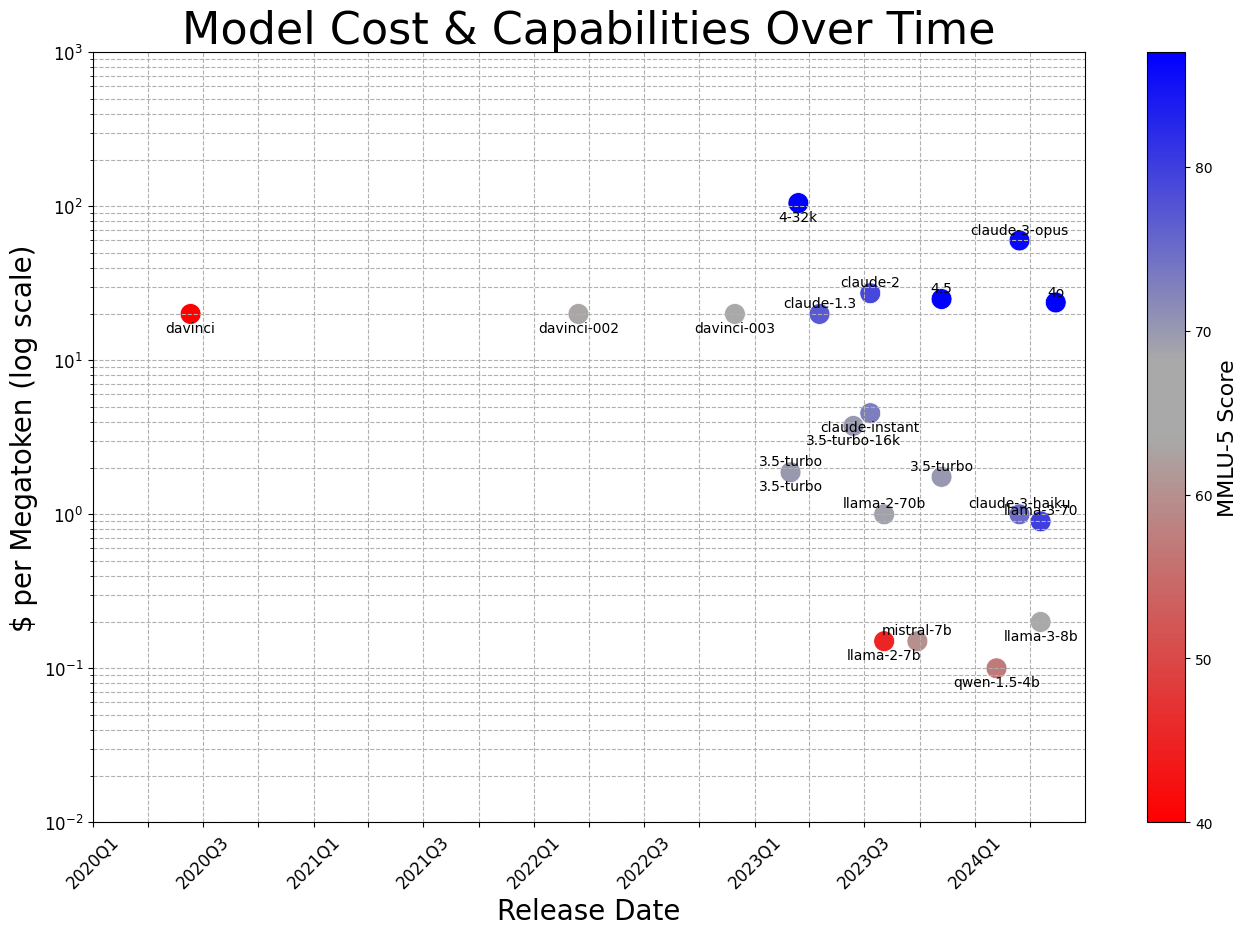
Within the 4 years for the reason that launch of OpenAI’s davinci mannequin as an API, the associated fee for operating a mannequin with equal efficiency on that activity on the scale of 1 million tokens (about 100 copies of this doc) has dropped from $20 to lower than 10¢—a halving time of simply six months. Equally, the associated fee to run Meta’s LLaMA 3 8B through an API supplier or by yourself is simply 20¢ per million tokens as of Might of 2024, and it has related efficiency to OpenAI’s text-davinci-003, the mannequin that enabled ChatGPT to shock the world. That mannequin additionally price about $20 per million tokens when it was launched in late November of 2023. That’s two orders of magnitude in simply 18 months—the identical timeframe by which Moore’s Legislation predicts a mere doubling.
Now, let’s take into account an utility of LLMs that may be very helpful (powering generative online game characters, a la Park et al) however shouldn’t be but economical (their price was estimated at $625 per hour right here). Since that paper was revealed in August of 2023, the associated fee has dropped roughly one order of magnitude, to $62.50 per hour. We’d count on it to drop to $6.25 per hour in one other 9 months.
In the meantime, when Pac-Man was launched in 1980, $1 of as we speak’s cash would purchase you a credit score, good to play for a couple of minutes or tens of minutes—name it six video games per hour, or $6 per hour. This serviette math suggests {that a} compelling LLM-enhanced gaming expertise will change into economical a while in 2025.
These tendencies are new, only some years previous. However there’s little motive to count on this course of to decelerate within the subsequent few years. Whilst we maybe deplete low-hanging fruit in algorithms and datasets, like scaling previous the “Chinchilla ratio” of ~20 tokens per parameter, deeper improvements and investments inside the info heart and on the silicon layer promise to select up slack.
And that is maybe a very powerful strategic truth: what’s a totally infeasible ground demo or analysis paper as we speak will change into a premium function in just a few years after which a commodity shortly after. We should always construct our methods, and our organizations, with this in thoughts.
Sufficient 0 to 1 Demos, It’s Time for 1 to N Merchandise
We get it, constructing LLM demos is a ton of enjoyable. With just some traces of code, a vector database, and a fastidiously crafted immediate, we create ✨magic ✨. And up to now yr, this magic has been in comparison with the web, the smartphone, and even the printing press.
Sadly, as anybody who has labored on transport real-world software program is aware of, there’s a world of distinction between a demo that works in a managed setting and a product that operates reliably at scale.
Take, for instance, self-driving vehicles. The primary automobile was pushed by a neural community in 1988. Twenty-five years later, Andrej Karpathy took his first demo journey in a Waymo. A decade after that, the corporate acquired its driverless allow. That’s thirty-five years of rigorous engineering, testing, refinement, and regulatory navigation to go from prototype to industrial product.
Throughout completely different components of trade and academia, now we have keenly noticed the ups and downs for the previous yr: Yr 1 of N for LLM purposes. We hope that the teachings now we have discovered —from techniques like rigorous operational methods for constructing groups to strategic views like which capabilities to construct internally—provide help to in yr 2 and past, as all of us construct on this thrilling new expertise collectively.
In regards to the authors
Eugene Yan designs, builds, and operates machine studying methods that serve prospects at scale. He’s presently a Senior Utilized Scientist at Amazon the place he builds RecSys for thousands and thousands worldwide worldwide and applies LLMs to serve prospects higher. Beforehand, he led machine studying at Lazada (acquired by Alibaba) and a Healthtech Collection A. He writes & speaks about ML, RecSys, LLMs, and engineering at eugeneyan.com and ApplyingML.com.
Bryan Bischof is the Head of AI at Hex, the place he leads the staff of engineers constructing Magic – the info science and analytics copilot. Bryan has labored everywhere in the information stack main groups in analytics, machine studying engineering, information platform engineering, and AI engineering. He began the info staff at Blue Bottle Espresso, led a number of initiatives at Sew Repair, and constructed the info groups at Weights and Biases. Bryan beforehand co-authored the e book Constructing Manufacturing Suggestion Programs with O’Reilly, and teaches Information Science and Analytics within the graduate faculty at Rutgers. His Ph.D. is in pure arithmetic.
Charles Frye teaches individuals to construct AI purposes. After publishing analysis in psychopharmacology and neurobiology, he obtained his Ph.D. on the College of California, Berkeley, for dissertation work on neural community optimization. He has taught 1000’s all the stack of AI utility improvement, from linear algebra fundamentals to GPU arcana and constructing defensible companies, via academic and consulting work at Weights and Biases, Full Stack Deep Studying, and Modal.
Hamel Husain is a machine studying engineer with over 25 years of expertise. He has labored with progressive firms similar to Airbnb and GitHub, which included early LLM analysis utilized by OpenAI for code understanding. He has additionally led and contributed to quite a few fashionable open-source machine-learning instruments. Hamel is presently an unbiased marketing consultant serving to firms operationalize Massive Language Fashions (LLMs) to speed up their AI product journey.
Jason Liu is a distinguished machine studying marketing consultant identified for main groups to efficiently ship AI merchandise. Jason’s technical experience covers personalization algorithms, search optimization, artificial information technology, and MLOps methods.
His expertise contains firms like Stitchfix, the place he created a suggestion framework and observability instruments that dealt with 350 million day by day requests. Extra roles have included Meta, NYU, and startups similar to Limitless AI and Trunk Instruments.
Shreya Shankar is an ML engineer and PhD scholar in pc science at UC Berkeley. She was the primary ML engineer at 2 startups, constructing AI-powered merchandise from scratch that serve 1000’s of customers day by day. As a researcher, her work focuses on addressing information challenges in manufacturing ML methods via a human-centered strategy. Her work has appeared in high information administration and human-computer interplay venues like VLDB, SIGMOD, CIDR, and CSCW.
Contact Us
We might love to listen to your ideas on this submit. You’ll be able to contact us at contact@applied-llms.org. Many people are open to varied types of consulting and advisory. We are going to route you to the right skilled(s) upon contact with us if applicable.
Acknowledgements
This collection began as a dialog in a bunch chat, the place Bryan quipped that he was impressed to put in writing “A Yr of AI Engineering”. Then, ✨magic✨ occurred within the group chat (see picture under), and we had been all impressed to chip in and share what we’ve discovered thus far.
The authors wish to thank Eugene for main the majority of the doc integration and total construction along with a big proportion of the teachings. Moreover, for main modifying tasks and doc path. The authors wish to thank Bryan for the spark that led to this writeup, restructuring the write-up into tactical, operational, and strategic sections and their intros, and for pushing us to assume larger on how we might attain and assist the group. The authors wish to thank Charles for his deep dives on price and LLMOps, in addition to weaving the teachings to make them extra coherent and tighter—you’ve gotten him to thank for this being 30 as a substitute of 40 pages! The authors admire Hamel and Jason for his or her insights from advising purchasers and being on the entrance traces, for his or her broad generalizable learnings from purchasers, and for deep data of instruments. And at last, thanks Shreya for reminding us of the significance of evals and rigorous manufacturing practices and for bringing her analysis and unique outcomes to this piece.
Lastly, the authors wish to thank all of the groups who so generously shared your challenges and classes in your personal write-ups which we’ve referenced all through this collection, together with the AI communities in your vibrant participation and engagement with this group.